MapReduce
Developed by Google circa 2004 to scale its search engine performance with the
exploding size of the internet (many new webpages being added daily).
Key innovations of MapReduce
Was pioneered by Google ~ 2004
- Motivated by streaming webpage processing for page indexing.
- Apache Hadoop (released in 2006, only 2 years later) adopted by industry
Impacts :
- Applied to a wide range of big data analytics problems very quickly.
- Hadoop Distributed File Systems (HDFS) became the industry standard for
Storing Big Data (also adopted by Spark later). - Motivated the design of Spark.
MapReduce at google
- Inputs to MapReduce (for this application) - large number of (new) webpages on a regular basis.
- Outputs from MapReduce: - The term frequency (TF) for each word on a page. - For each word observed, update the inverse document frequency (IDF).
MapReduce cluster requirements
MapReduce requires:
- Requires specification of M worker nodes for map.
- Requires specification of R works nodes for reduce.
- One master node for coordination and planning.
MapReduce provides: - (key, value) pairs
Resource allocations
MapReduce performs scalable operations through “look-ahead”
Planning:
- Partitions keys into R groups - with each group having its reduce worker.
- Partitions document/webpage corpus to M groups - with each group having its map worker.
MapReduce then performs aggregation through: - Each map worker generates R (key, value) pairs and saves them to disk.
- Each reduce worker aggregates M files (one from each Map worker), all for the group of keys assigned to the Reduce worker.
Skipped to divide and conquer to catch up
MapReduce - Divide and conquer
- Idea: Split your large data across computing resources to get acceleration.
- Very well suited for “Embarrassingly parallel” problems such as local transformations to a data (for e.g. find sum of rows in a large file - send subsets of rows to different nodes)
- Several problems require some form of aggregation across resources. MapReduce allows for this type of aggregation to be performed in a scalable manner.
Partition
Each node is the first counting step (map worker) generates 26 output files, one for each key/word subspace (plan ahead for scalable aggregation). The aggregation task is assigned to the reduce worker one for each key subspace.
Boundary conditions
When analyzing gene sequences MapReduce fails as gene sequences can be chopped up thus the information is lost maybe even the sequence we’re looking for it wouldn’t crash just return errors depending on the situation. MapReduce computations must be embarrassingly parallel as the computation must require no communication or coordination between different map tasks, or between different reduce tasks.
Innovation
The key innovations of MapReduce are:
- Input data division into chunks that are each allocated to different workers.
- Partition the space of keys into subspaces that are each associated with different reduce workers.
- A map-step where map workers generate separate files for each subspace of keys that can be read by reduce workers
The combination of these three steps leads to dramatic reduction in
Time-to-solution for several classes of problems (with small intermediate sizes of
Data, such as counting problems)
Plan-Ahead
The combination of partitioning and intermediate generation of pairs according to the number of reduce workers is called Plan-Ahead
Map in MapReduce
The map in MapReduce is more than simply a Map operation
Divides the input data into partitions/chunks, and distributes the application of map functions among a set of computers/nodes in a cluster- unsurprising
Plans-ahead/prepares for the following reduce step so that the output key-value pairs is distributed in multiple output files scalably.
MapReduce and Hadoop
Implementing MapReduce in a Cluster requires:
- A file system that supports Big Data (e.g., allow a big dataset to be stored in
multiple “chunks”) -> HDFS - A cluster manager that assigns data/task to nodes in the cluster -> Yarn
- Efficient detection and recovery from failures of any node (robustness
requirement)
Robustness
Requires the concept of a master node:
- A
special nodethat assigns map tasks/data, reduce tasks to nodes in a cluster. - The
special nodealso monitors other nodes (i.e., map workers and reduce workers) for detecting failures and for orchestrating recovery.
How do we get robustness? - If the Master node detects any failed map worker:
- The Master dynamically reassigns all of their tasks to other nodes.
- The Master also informs all Reduce workers about the changed location of the Map worker (and its intermediate files)
- If the Master detects any reduce worker fails
- The Master dynamically reassigns all of their tasks to another reduce worker
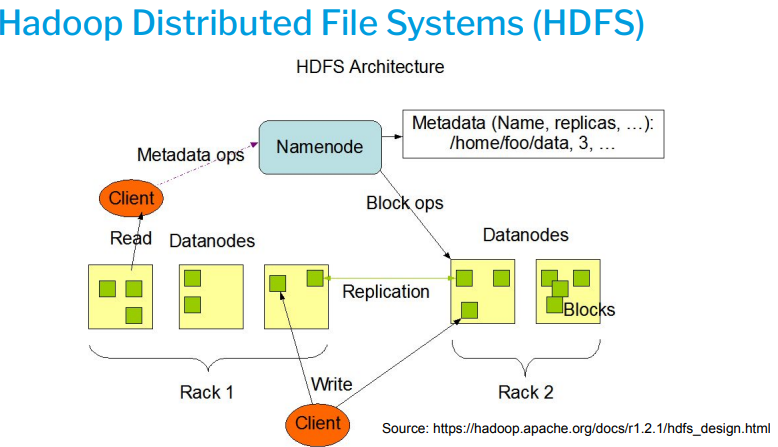
Hadoop Distributed File System (HDFS)
- A distributed file system (DFS) that can run using commodity hardware (e.g. PCs). DFS implies data that is stored on separate physical locations but with communications (read/write)
Usefulness of HDFS
especially useful in the early days of Big Data to allow organizations to leverage old PCs to test/evaluate big data processing opportunities.
- Supports high-throughput access to data (e.g., for gathering/storing streaming data).
- Supports the storage of large data sets, which can be distributed among multiple machines/racks.
- Supports the recovery of data from machine/disk failure. - Replicates data across machines/racks for fault-tolerance.
- Uses a NameNode to map file names (and their copies) to actual locations.
Hash-functions
- A hash function takes the key as input and computes a hash value, which is typically an integer. This hash value is used to determine the index (or position) where the corresponding value will be stored in the hash table.
- In the context of storing information in computer memory, hash functions are used to efficiently organize and retrieve data from data structures known as hash tables or hash maps. These data structures are designed to provide fast access to data based on a key, allowing for rapid insertion, deletion, and retrieval of information.
- Output of MapReduce is not reversible as the hash is lost in the process
Data partitioning
Hash functions are used to determine which split or partition a particular <key,value> pair should go to. By applying a hash function to the key, the framework can determine the partition where the data should be sent.
Shuffling and Sorting
: In this phase, the framework collects the output from all mapper tasks and sorts it based on the keys. Here, hash functions are used again to group together <key, value> pairs with the same key
Data Retrieval in Reduce Phase
In the reduce phase of MapReduce, each reducer task takes a set of grouped <key, value> pairs and processes them to generate the final output using the hash function.
Applications of MapReduce
Embarrassingly parallel applications that can be decomposed into a map step and a reduce (aggregation) step
The intermediate results of the map step can be represented as key-value pairs
The aggregation of reduce step groups intermediate results by keys
- Data transformations and feature engineering for AI modeling.
- Text Analysis and Natural Language Processing (NLP)
- Image and Video Processing
- Graph Analysis and Social Network Analysis
- Log Analysis and Anomaly Detection
- Genomics and Bioinformatics
- Recommendation Systems
- Large-Scale Data Mining
- Spatial Analysis and GIS (Geographic Information Systems)
- Data Aggregation and Summarization
- Fraud Detection
Limitations of MapReduce
- MapReduce is NOT designed for iterative big data analytics.
- If we use MapReduce in a loop, there is no general/flexible way to save/reuse data between iterations.
- Cost of iterative big data analytics using MapReduce is high. - Note: This limitation motivates the design of Spark.
- Any problem that introduces a ‘race-condition’
Distributed computing by dividing a task into
- A completely decomposable (Map) phase
- A key-based aggregation (Reduce) phase
Key-guided structure
A key is the dependency between the two phases interpret <key,value> pairs as intermediate results of Map to facilitate reduction phase
Coordinated Output/Input
Each Mapper generates n files - one for each Reducer (reduce the cost of copying files)