MapReduce and Lazy Evaluation in Spark
Related: Software engineering | Cloud computing
Key Concepts: Understanding how Spark optimizes big data processing through lazy evaluation and RDD transformations.
Conventional Evaluation
Each statement in a program is executed immediately after it is loaded into CPU.
Lazy Evaluation
A statement in a program is NOT executed immediately; its execution is postponed after some other statements have been evaluated.
Lazy evaluation in Spark assists with optimization of computation. Remember the adage
“Computation movement is cheaper than data movement”
RDDs and lazy evaluation
- A graph of data transformations/action form a lineage chain.
- Transformations are not immediately evaluated. Physical Resource (memory, executor) for RDD is not allocated either until the action step gets evaluated (i.e., lazy evaluation). -
- All necessary information for computing a transformation is stored in its RDD. - RDD contains both computing information and data partition information. -
- The lineage chain is constructed incrementally, with one RDD added after its transformation is evaluated. -
- When a lineage chain reaches an action, it executes all of the transformations earlier on the chain.
RDDs and immutability
- All transformation operations in Spark generate RDDs. RDDs are immutable
- Invoking computation of a transformation-action chain does NOT change the RDD, but generates new RDDs.
- An RDD can be used in multiple transformation-action chains.
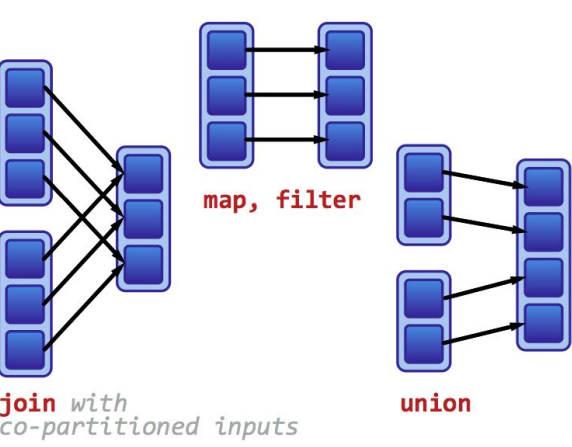
RDDs and data dependencies
- Narrow (i.e., loose) dependency: -
- Example: Map: The child partition RDDs uses only the RDDs of the parent partition. -
- One-to-one mapping from partitions in parent to partitions in child. -
- More efficient to be pipelined -
- Recovery/Transformations are faster -
- Wide (i.e., strong) dependency -
- Example: Join: Many-to-many mapping from partitions in parent to partitions in child. -
- More costly (remember “Race conditions”) -
- Recovery may require complete re-execution of the pipeline
RDDs and data dependencies
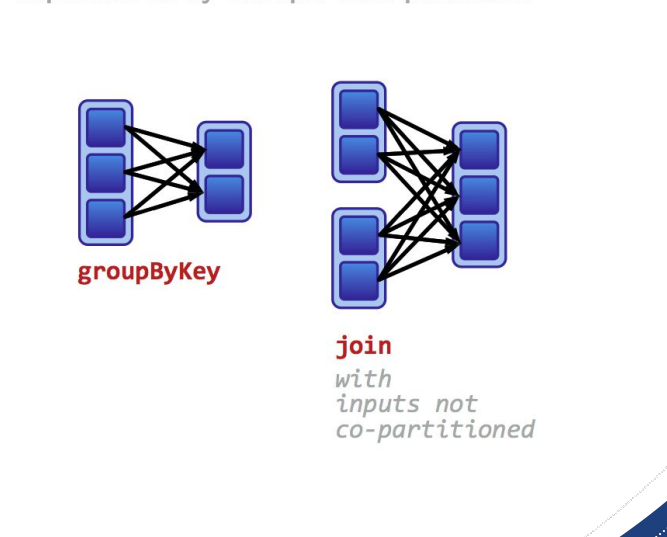
Narrow dependencies:
Each partition of the parent RDD is used by at most one partition of the child RDD.
Wide dependencies
Each child partition depends on multiple partitions of the parent RDD.
Key-value RDDS
- Enables grouping, counting, and other aggregations by keys -
- A Key-value RDD can be generated by map or flatMap (explained later) whose lambda function returns a list of two elements: (, ) -
- A Key-value RDD can be aggregated using -
- reduceByKey -
- groupByKey -
- You will see examples of this in your second Lab
Spark operations
- Steps that can be postponed are called transformations (e.g., map, reduceByKey). -
- Transformations generate an output RDD from (one or more) input RDD(s) -
- Steps that can NOT be postponed are called actions (e.g., saveAsTextFile). -
- Actions aggregate multiple RDD’s to return a result or write to storage -
- The execution of transformations are postponed until an action that uses the output of the transformation (directly or indirectly). -
- Consequently: Information later in a pipeline can be used to optimize partition, task assignment (to executors), etc for a transformation step earlier in the pipeline.
Examples of transformations -
.map(function f): Parse each element of the input RDD through f, returns an output RDD of same structure. - .flatmap(function f): Parse each element of the input RDD through f, flatten and return an output RDD with flattened list (structure may change). - .filter(function f): Returns an output RDD that (after lazy evaluation) includes elements of the input RDD that is “TRUE”for the function f. - .join(inputRDD2): Joins two input RDDs on their keys (after lazy evaluation), returns an output RDD.
Examples of actions
- .collect(): returns the actual content of the RDD -
- .count(): returns the total number of elements in the input RDD -
- .take(n): returns the first n elements of the input RDD -
- .saveAsTextFile(path):Save the content of the RDD in the specified directory.
Spark operations and lazy evaluations
token_1_RDD = tokensRDD.map(lambda x: (x, 1) )
token_1_RDD # object created, but NOT evaluated/computed since we do not know how to best partition it for following steps.
token_count_RDD = token_1_RDD.reduceByKey(lambda x, y: x+y,4)
token_count_RDD # object created, but NOT evaluated/computed. However, Spark nowknows the output,
token_count_RDD # is better to be partitioned by keys into 4 chunks.
token_count_RDD.saveAsTextFile(“/storage/home/rmm7011/Lab2/token_count.txt”)
Difference between RDDs and Objects
- An assignment statement to an object typically computes the value/content of the object and store them in the object.
- However, an assignment statement to an RDD in Spark does NOT compute the value/content of the object
- The assignment statement only creates an RDD object that contains vital information needed (later) for computing the RDD:
- The input data (another RDD(s) or the path of an input file)
- The method (e.g., map, flatMap) of the transformation
- The function (e.g., lambda function) used in the transformation
- How the output data should be partitioned, and how many partitions.
PySpark
Two Modes of Running Spark:
- Local Mode: Pyspark in Jupyter Notebook (for developing and debugging code using small dataset)
- Cluster Mode: spark-submit in a YARN/HDFS/Standalone cluster (for deploying, evaluating, and optimizing Spark for processing Big Data). We will use standalone cluster given ICDS uses slurm
Driver program and SparkContext
- Sparks Driver program is like the master node in MapReduce
- A special object, called SparkContext provides critical info about the job
SparkContext
SparkContext serves as the entry point for interacting with a Spark cluster. It represents the connection to the Spark cluster manager and coordinates the execution of distributed computations across the cluster. The SparkContext provides the necessary configuration settings for your Spark application and manages the resources, such as memory and computing cores, needed for executing Spark jobs.
Terminology
- A Node: A physical machine in a HPC cluster, typically consisting of multiple processors.
- Executor: Like a worker in MapReduce, each of which can be assigned to one or multiple Spark tasks.
- A Spark task is a transformation operation or an action operation coupled with the data partition associated with it.
- Multiple tasks can be assigned to the same executor.
Vanilla MapReduce vs. Spark’s MapReduce
| Plan-ahead in MapReduce | Lazy Evaluation in Spark | Impacts of Spark Innovations |
|---|---|---|
| Map Workers | Executors assigned to perform a transformation | Transformation is broader than Map, including map, filter, read an input file, etc. |
| Reduce Workers | Executors assigned to perform an action | Action is broader than Reduce, including count, collect, save output in a distributed file system. |
| Partition of keys into R output files of Mappers | Various ways to optimize: (1) partitioning data into RDDs, (2) assigning tasks (RDD + transformation/action) to executors, (3) key-based partition of key-value pairs, and (4) save/reuse RDD across iterations using persist/cache. |
A more flexible, powerful, developer-friendly programming model for Big Data with effective and scalable resource allocation. |
Spark in local mode
- Runs on a single computer
- Uses a small part of the total data
- Useful for debugging as you can work with a small dataset and test your features
- The code should still be designed for scale up (using multiple cores for processing Big Data) in a cluster.